Linux┊字符设备和块设备的区别?
今天学了下Linux下文件的备份,如dump命令,然后在/dev里面查看文件时发现了有些文件的标识是b与c,不是通常的d,然后去网上找了找资料,就放这了吧。![]()
设备文件分为Block Device Driver和Character Device Drive两类。Character Device Drive又被称为字符设备或裸设备raw devices; Block Device Driver通常成为块设备。而Block Device Driver是以固定大小长度来传送转移资料 ;Character Device Driver是以不定长度的字元传送资料 。且所连接的Devices也有所不同,Block Device大致是可以随机存取(Random Access)资料的设备,如硬碟机或光碟机;而Character Device刚好相反,依循先後顺序存取资料的设备,如印表机 、终端机等皆是。
/dev/dsk对应的为块设备,文件系统的操作用到它,如mount。/dev/rdsk对应的为字符设备(裸设备,rdsk的r即为raw),fsck newfs等会涉及到。一般我们的操作系统和各种软件都是以块方式读写硬盘,这里的块是逻辑块,创建文件系统时可以选择,windows里叫簇。可看newfs or mkfs的manual。oracle是比较常见的字符方式读写硬盘。
Character Device Files
The file type “c” identifies character device files. For disk devices,character device files call for I/O operations based on the disks smallest addressable unit, or sectors. Each sector is 512 bytes in size.
Block Device Files
The file type “b” identifies block device files. For disk devices, block device files call for I/O operations based on a defined block size. The block size depends on the particular device, but for UFS file systems,the default block size is 8 Kbytes.
转载自:http://www.360doc.com/content/11/0420/14/1317564_111004478.shtml
Python小程序(4)检查文件与文件夹
Python中提供了很多这样的函数:返回有关文件系统中文件与文件夹信息。
常见的有:os.listdir(p),os.getcwd(),os.isfile(p),os.isdir(p),os.stat(fname)
其中cwd的英文全称是:current working directory,即当前工作目录的意思。
os.stat返回的是fname的信息,如最后一次修改时间,大小等。
listdir,isfile,isdir,望文生义,既知道是列出指定文件夹p中所有文件和文件夹的名称,isfile(p),isdir(p)则是判断p是否为单一文件或者是文件夹。
import os
def list_cwd():
""" Return current working directory
"""
return os.listdir(os.getcwd())
def files_cwd():
""" Return files
"""
return [p for p in list_cwd() if os.path.isfile(p)]
def folders_cwd():
""" Return folders
"""
return [p for p in list_cwd() if os.path.isdir(p)]
def list_py(path = None):
""" Return the files if it's endswith '.py'
"""
if(path == None):
path =os.getcwd()
return [fname for fname in os.listdir(path)
if os.path.isfile(fname)
if fname.endswith('.py')]
def size_in_bytes(fname):
""" Return the size of a file
"""
return os.stat(fname).st_size
def cwd_size_in_bytes():
""" Return the total sizes of files
"""
total = 0
for name in files_cwd():
total += size_in_bytes(name)
return total
Python小程序(3)之字典的使用
Python中字典感觉和C++中的map差不多嘛。当单位插入到字典中时,顺序可能会改变,应是根据键的字典序来排列的。
字典就那么几个函数,如:
d.pop(); d.items(); d.values(); d.keys(); d.copy();d.clear(); d.update(e); (e是键-值类型)
个人认为d.items(); d.get(key); d.update(e); d.pop(); d.copy();d.clear()比较重要,记住几个常用的就行了。
import re
def main():
color = {'red':1, 'blue':2, 'gress':3, 'orange':4}
map = color.copy()
print('color:', color)
print('map:', map)
lst = []
k = color.values()
for i in k:
print('values:', i, end = ' ')
if i >= 1:
lst.append(i)
print('\nlst:', lst)
print('\n')
map.clear()
color.clear()
####################################################
map = {6:'red', 5:'blue', 4:'gress', 3:'orange', 2:'gresssss!', 1:'gressss!!'}
color = map.copy()
print('color:', color)
print('map:', map)
result = []
k = map.items()
for i in k:
print('items:', i, end = ' ')
d = re.match('gress', i[1])
if d:
result.append(i[1])
print('\nresult:', result)
map.clear()
color.clear()
The Zen of Python
在Python3.x中输入import this就出现以下内容:直译为Python的禅宗,即Python之禅。
The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those! 优美胜于丑陋(Python 以编写优美的代码为目标) 明了胜于晦涩(优美的代码应当是明了的,命名规范,风格相似) 简洁胜于复杂(优美的代码应当是简洁的,不要有复杂的内部实现) 复杂胜于凌乱(如果复杂不可避免,那代码间也不能有难懂的关系,要保持接口简洁) 扁平胜于嵌套(优美的代码应当是扁平的,不能有太多的嵌套) 间隔胜于紧凑(优美的代码有适当的间隔,不要奢望一行代码解决问题) 可读性很重要(优美的代码是可读的) 即便假借特例的实用性之名,也不可违背这些规则(这些规则至高无上) 不要包容所有错误,除非你确定需要这样做(精准地捕获异常,不写 except:pass 风格的代码) 当存在多种可能,不要尝试去猜测 而是尽量找一种,最好是唯一一种明显的解决方案(如果不确定,就用穷举法) 虽然这并不容易,因为你不是 Python 之父(这里的 Dutch 是指 Guido ) 做也许好过不做,但不假思索就动手还不如不做(动手之前要细思量) 如果你无法向人描述你的方案,那肯定不是一个好方案;反之亦然(方案测评标准) 命名空间是一种绝妙的理念,我们应当多加利用(倡导与号召)
Python小程序(2)
python函数,有关默认函数的一个要点是,函数可根据需要使用任意数量的默认参数,但带默认值的参数不能位于没有默认值的参数前面。
比如说:
def greet(name, greeting = 'Hello '):
print(greeting + name+'!')
#def greet(greeting = 'Hello', name):
# print(greeting, name+'!')
Python小程序(1)
偷闲学了以下Python,Python中对缩进要求很特别严,for if else while后面接的都是:
我用的是python3.1,下载地址在传送门
n = int(input('Enter an interger >=0 : '))
fact = 1
for i in range(n):
fact = fact*(i+1)
print(str(n)+ ' factorial is ' + str(fact))
Linux中root密码忘记了如何重置
今天NC忘记了root密码,然后去网上找了如何解决的方法,太杂了,还是自己记录一下吧。
如何重置root密码,通过BIOS管理菜单进入Ubuntu的recovery mode,按e进入编辑模式,然后找到ro ..noquite 什么什么的.., 把它然后改为rw single init=/bin/bash 即可,然后按Ctrl+x保存之后,然后在命令行输入passwd重置密码即可。
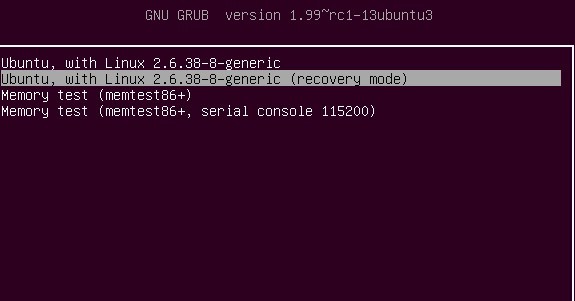
如何解决Ubuntu重复进入登录界面
最近几天在学Linux,昨天发现输入用户名、密码之后重复进入登入界面,就是不能登录进图形界面,试了试网上许多方法,都不管用,最后还是解决了这个问题。我的原因不是网上常说的环境变量引起的,我也不知道是什么原因。
如果网上的环境变量不奏效的话,可以参考下我的解决的方法:用guest账号登录,把原来的管理员账号删除,重置一个管理员账号即可。
POJ 2949 Word Rings
题意:给你一些单词,如果一个单词的后两个字母和另外一个单词的前两个字母一样,那么这两个单词就可以连在一起,然后让你求单词成环之后,最大的平均权值。
解法:求平均权值最大的环路? 记得一本书上说过,假如所有的边都在环中,其实就是:E1+E2+E3+E4+....+En = mid*n;转换一下即为:E1-mid+E2-mid+...En-mid = 0;这是权值相等的时候。 要使得mid最大,那么我们可以把E1-mid做为原先图的边。如果有正环存在,说明权值可以继续增大。 二分枚举mid即可。
要用stack来进行入队、出队操作才可以过,要不是会TLE。原因在一篇论文集上有所说明,我认为只需掌握怎么写就行了。
#include <iostream>
#include <cstdlib>
#include <cstdio>
#include <string>
#include <cstring>
#include <cmath>
#include <queue>
#include <vector>
#include <algorithm>
#include <set>
#include <map>
#include <stack>
using namespace std;
int k, n, m;
const int maxn = 2010;
const int maxm = 1010*1010*2;
const int INF = 0x3f3f3f3f;
double d[maxn];
struct Edge
{
int u, v;
double w;
int next;
}edge[maxm];
int cnt;
int first[maxn];
void read_graph(int u, int v, double w)
{
edge[cnt].v = v, edge[cnt].w = w;
edge[cnt].next = first[u], first[u] = cnt++;
}
bool inq[maxn];
double L, R;
int spfa(double mid)
{
stack<int> Q;
for(int i = 1; i <= k; i++)
{
d[i] = 0;
Q.push(i);
inq[i] = 1;
}
int CNT[maxn] = {0};
while(!Q.empty())
{
int x = Q.top(); Q.pop();
inq[x] = 0;
for(int e = first[x]; e != -1; e = edge[e].next)
{
int v = edge[e].v;
double w = edge[e].w;
if(d[v] < d[x]+w)
{
d[v] = d[x]+w;
if(!inq[v])
{
inq[v] = 1;
if(++CNT[v] > k) return 1;
Q.push(v);
}
}
}
}
return 0;
}
void init()
{
cnt = 0;
memset(first, -1, sizeof(first));
}
int ord(char x, char y)
{
return (x-'a')*26+y-'a'+1;
}
int have_cycle(double mid)
{
for(int i = 0; i < m; i++) edge[i].w -= mid;
int flag = 0;
if(spfa(mid)) flag = 1;
for(int i = 0; i < m; i++) edge[i].w += mid;
return flag;
}
const double eps = 1e-2;
char word[1010];
int vis[3010];
int main()
{
while(scanf("%d", &m))
{
if(!m) break;
init();
memset(vis, 0, sizeof(vis));
L = 0, R = 0;
k = 0;
for(int i = 0; i < m; i++)
{
scanf("%s", word);
int len = strlen(word);
int a = ord(word[0], word[1]);
int b = ord(word[len-2], word[len-1]);
if(!vis[a]) vis[a] = ++k;
if(!vis[b]) vis[b] = ++k;
R = max(R, len*1.0);
read_graph(vis[a], vis[b], len*1.0);
}
double ans = -1;
while(R-L >= eps)
{
double mid = L+(R-L)/2.0;
if(have_cycle(mid))
{
ans = mid;
L = mid;
}
else R = mid;
}
if(ans == -1) printf("No solution.\n");
else printf("%.2f\n", ans);
}
return 0;
}
编程珠玑(第二版)2.1节第三个问题之变位词的实现
今天翻了翻编程珠玑这本书,整体而言还是比较有趣的。可以说给了读者另一种认识编程的角度吧。
#include <iostream>
#include <cstdlib>
#include <cstdio>
#include <string>
#include <cstring>
#include <cmath>
#include <queue>
#include <vector>
#include <algorithm>
#include <set>
#include <map>
using namespace std;
const int maxn = 1100;
vector<string> A[maxn];
map<string, int> hash;
int main()
{
hash.clear();
string str[110];
int n = 0, k = 0;
while(cin>>str[n] && str[n] != "END")
{
string t = str[n];
sort(t.begin(), t.end());
if(!hash[t]) hash[t] = ++k;
n++;
}
for(int i = 0; i < n; i++)
{
string t = str[i];
sort(t.begin(), t.end());
A[hash[t]].push_back(str[i]);
}
for(int i = 0; i < n; i++)
{
for(int j = 0; j < A[i].size(); j++)
{
cout<<A[i][j]<<" ";
}
cout<<endl;
}
system("pause");
return 0;
}
/*
input:
ptos
pots
stop
tops
XXXX
END
output:
ptos pots stop tops
XXXX
*/
POJ 3414 Pots
好久没发关于ACM的文章了,以前的博客几个月没用了。今天随便水了一题,顺便发第一篇在这博客上的ACM的文章。
#include <iostream>
#include <cstdlib>
#include <cstdio>
#include <string>
#include <cstring>
#include <cmath>
#include <queue>
#include <vector>
#include <algorithm>
#include <set>
#include <map>
using namespace std;
//fill 1 0
//drop 1 1
//fill 2 2
//drop 2 3
//pour(1, 2) 4
//pour(2, 1) 5
struct node
{
int v[2];
string step;
int ans;
};
int A, B, C;
bool vis[110][110];
node bfs()
{
memset(vis, 0, sizeof(vis));
node cur, next;
cur.v[0] = 0, cur.v[1] = 0, cur.step = "", cur.ans = 0;
vis[0][0] = 1;
queue<node> Q;
Q.push(cur);
while(!Q.empty())
{
cur = Q.front(); Q.pop();
int a = cur.v[0], b = cur.v[1];
if(a == C || b == C) return cur;
if(a != A && !vis[A][b]) //fill 1
{
next = cur;
next.v[0] = A;
vis[A][b] = 1;
next.step += '0', next.ans++;
Q.push(next);
}
if(a > 0 && !vis[0][b]) //drop 1
{
next = cur;
next.v[0] = 0;
vis[0][b] = 1;
next.step += '1', next.ans++;
Q.push(next);
}
if(b != B && !vis[a][B]) //fill 2
{
next = cur;
next.v[1] = B;
vis[a][B] = 1;
next.step += '2', next.ans++;
Q.push(next);
}
if(b > 0 && !vis[a][0]) //drop 2
{
next = cur;
next.v[1] = 0;
vis[a][0] = 1;
next.step += '3', next.ans++;
Q.push(next);
}
if(b != B && a+b < B && !vis[0][a+b]) //pour(1, 2)
{
next = cur;
next.v[0] = 0, next.v[1] = a+b;
vis[0][a+b] = 1;
next.step += '4', next.ans++;
Q.push(next);
}
if(b != B && a+b > B && !vis[a-B+b][B])
{
next = cur;
next.v[0] = a-B+b, next.v[1] = B;
vis[a-B+b][B] = 1;
next.step += '4', next.ans++;
Q.push(next);
}
if(a != A && a+b < A && !vis[a+b][0]) //pour(2, 1)
{
next = cur;
next.v[0] = a+b, next.v[1] = 0;
vis[a+b][0] = 1;
next.step += '5', next.ans++;
Q.push(next);
}
if(a != A && a+b > A && !vis[A][b-A+a])
{
next = cur;
next.v[0] = A, next.v[1] = b-A+a;
vis[A][b-A+a] = 1;
next.step += '5', next.ans++;
Q.push(next);
}
}
node b;
b.ans = -1;
return b;
}
void print(node a)
{
int n = a.step.length();
printf("%d\n", a.ans);
for(int i = 0; i < n; i++)
{
char c = a.step[i];
switch(c)
{
case '0': printf("FILL(1)\n"); break;
case '1': printf("DROP(1)\n"); break;
case '2': printf("FILL(2)\n"); break;
case '3': printf("DROP(2)\n"); break;
case '4': printf("POUR(1,2)\n"); break;
case '5': printf("POUR(2,1)\n"); break;
default: break;
}
}
}
int main()
{
while(~scanf("%d%d%d", &A, &B, &C))
{
node ans = bfs();
if(ans.ans == -1) { printf("impossible\n"); continue ; }
print(ans);
}
return 0;
}
生命是一种过程
生命只是一种过程,老去的生命终有一天会被新生的生命所取代,而在这段旅程中,最重要的是每天的开心与充实。
Life is just like a journey. It is no doubt that there exist one day that the old things will be replace by the new things. So the meaning of life is that you are happy and feel fulfilled in this journey.